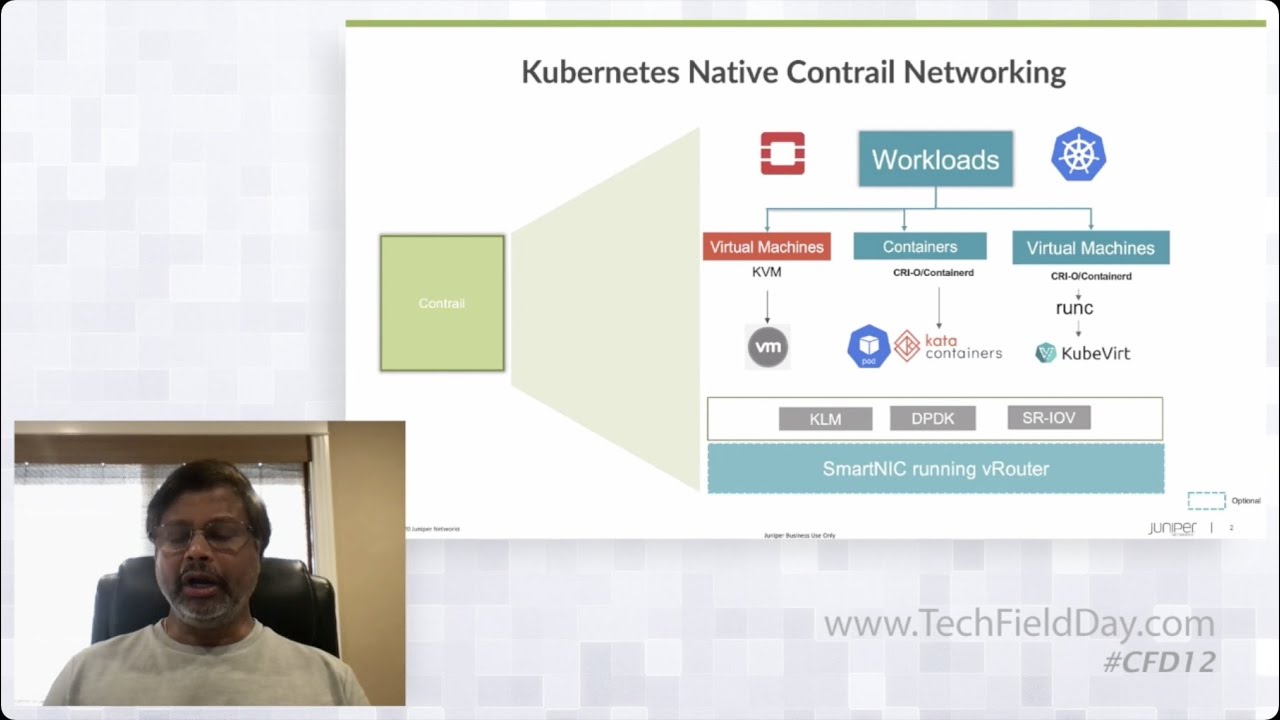
Juniper Networks Contrail Cross-Cluster Virtual Networking Demo

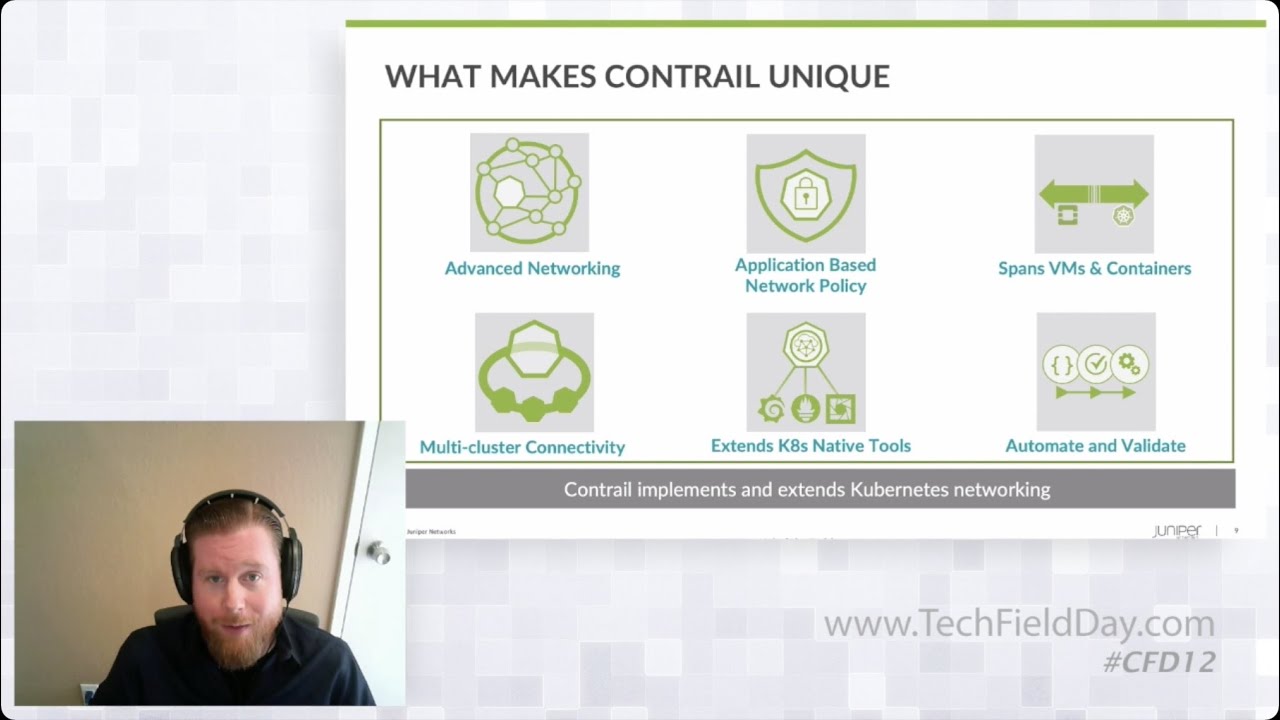
Virtual Demo: Contrail Cross-Cluster Networking
If you are interested in learning more about Contrail Networking’s cross-cluster virtual networking, then this demo by Juniper’s Michael Henkel is for you.
You’ll learn
How Contrail and Kubernetes resources interact together
How it provides added value in terms of load balancing
How operators interact with Contrail as a system
Who is this for?
Host
Transcript
0:09 my name is michael henkel i'm working in the pathfinder team in the city organization and i'm really happy to have the
0:16 opportunity to show you some of the capabilities of contrail and as i mentioned just before my statement
0:22 um one of things i want to demonstrate today is how contrail and kubernetes resources
0:29 are interacting together and how we can provide some added value in terms of
0:37 late relay for functionality around load balancing and also
0:43 one purpose of the demonstration is going to show you how
0:48 operators are going to interact with contrail as a system and how natively that works by just
0:55 following the standard ways on how people are operating the kubernetes cluster what i'm going to demonstrate
1:02 today is load balancing basically so
1:07 i have three clusters set up cluster one two and three and they are
1:12 represented here in canon s windows so we have the first cluster second cluster down here and third
1:18 cluster and what we want to achieve is that on cluster one and cluster two we
1:24 are creating an application as part of a stateful set which is going to be front-ended by an incross controller on
1:29 both clusters and cluster 3 acts as some kind of a client cluster which is communicating with the applications on
1:36 cluster 1 and cluster 2. and the goal is to load balance that traffic so when cluster tree is trying to access the
1:42 application half of the traffic is going to plus the one the other half of the traffic is gonna go to um cluster two and um that
1:50 is gonna be achieved without using any kind of external load balancer um so that's going to demonstrate some of the
1:56 multi-cluster capabilities of contrail using a concept we call the control plane federation where we exchange
2:02 dynamically routes between all clusters and it's solving a common problem that
2:08 if you have multiple clusters they all provide interest how can i make this increase accessible
2:15 in a load balanced fashion to the outside world the the resource of the features we will
2:20 work with in contrail are virtual networks subnets route targets pgp routers you
2:27 don't need to memorize all of that it's just again the purpose here is to show you how we
2:32 interact with those resources and finally what we will end up with is a vcmp load balancing
2:40 from the source in cluster 3 towards the destinations in cluster 1 and cluster 2.
2:46 the way i've laid out this demonstration is that we will first just create some standard
2:53 kubernetes resources without any control specific configuration once we have all those resources set up then we will go
2:59 to the contrary resources and create virtual networks and subnets and we'll see how the contrary resource and the kubernetes
3:06 resources are going to interact with each other okay so let's start with the first piece which is to create the
3:13 application on custom one and cluster two so it's pretty standard a stateful set it's going to create two replicas
3:20 and the application is pretty simple it's just going to report back the name of the pot and the name of the cluster
3:28 which is injected by an environment variable down here that application is front-ended by a standard service so we
3:35 are going to create this one on the first cluster
3:41 so we can see here the first replica is coming up doing this on the second cluster as well
3:51 so this one is coming up down here it's going to take a couple of seconds to pull the container images
4:00 and at the same time you can see a service has been created which is called
4:06 my service which is simply listening on port 8080
4:16 so the first port is running second part is being created right now in the meanwhile what we can do is
4:22 to install the increase controller on cluster one and cluster two
4:28 um again standard installation just taken from the manual online nothing
4:34 specific over here so we are just installing it off the internet on the first cluster
4:42 so when we go to all namespaces we can see that the increase controllers and the admission
4:48 controllers are being created on the first cluster and now we are going to do the same
4:53 thing on the second cluster and again if there's any question in
4:58 between don't be shy and interrupt me at any time so what we then will see
5:04 in the services is that we created the standard service for the increase controller again i just took the
5:11 standard manifest for the inquest controller and once we have our increased pots running
5:18 double check here increase controller is coming up we can create an increase and what that
5:23 increase is doing is basically it's connecting the service with the um
5:30 the service you create for the application with the inquest controller so basically it makes all requests for this host
5:38 being forwarded to the application front-ended by the service over here
5:44 so let's do that for the first cluster
5:49 and let's do that also for the second cluster
5:55 so up to this point everything was standard kubernetes um there is no
6:00 contrail resource involved in here besides that the overlay network in
6:06 which the applications are running is provided by contrail itself
6:15 again everything is stock kubernetes we installed an application with a service we installed increase controller we
6:22 create an inquest and we will end up with that kind of deployment over here
6:28 what we are now going to do is we create a additional service network so we have
6:34 our default service network which is part of every default installation um like we do have pod networks again
6:40 part of every default installation when you install kubernetes you add control so cni
6:45 you will end up with a default service network and you will end up with a default port network we are going to add
6:52 a second service network this is going to be the service network through which
6:57 we will make the increase available to the outside you could do the same thing with the default service network but for now
7:04 we want to keep the service the default service network internal to the cluster and we want to use a separate service
7:09 network we can expose to the outside so what we will do here is that's the first time we are actually creating a contrary
7:16 resource in order to create a virtual network we need to do two things we need to create
7:22 a subnet and the subnet is pretty much straightforward it simply contains a cider which provides the subnet
7:29 information it can be we can put more configuration in here we can define
7:35 the gateway and a couple of more attributes of the subnet but for our purpose here it's just enough to provide
7:42 the slider gateway will be auto allocated it's starting with the first ip address in the subnet and the second part is to
7:49 create the actual virtual network they have to be the same name space and
7:55 we are referencing that subnet in the spec itself so if you can see here
8:02 the name and the namespace of that subnet reference is matching the
8:07 subnet name and namespace one thing to highlight on the virtual network is that
8:12 we are assigning this attribute here um a route target and that is very specific to pgp
8:20 just for now take it as an identifier of that virtual network it's just a
8:26 unique id which is being used within bgp to identify
8:31 if two virtual networks should be allowed to communicate with each other
8:37 the format looks a little bit awkward but that's how um the road targets are
8:42 defined in bgp again just take it as a unique identifier for that virtual network so let me create
8:48 that subnet and that virtual network on the first cluster
8:54 and let me do the same thing on the second cluster
9:01 and now we can go into our virtual networks
9:09 and you can see that we do have one virtual network which is called increasvion
9:15 and the same thing over here and we have it over here and it's in
9:21 success state which means we are ready to use this virtual network now what we will do is
9:28 we are basically moving the connection of the increase controller of
9:33 the default service network onto the new service network we just
9:39 created again that's the network we want to use for external reachability
9:44 and that is quite interesting because all we need to do is we need to change
9:50 the spec of the incros controller itself sorry the
9:56 spec of the service for the inquest controller itself so basically right now and we can demonstrate that
10:03 probably over here when you install the inquest controller
10:09 as a default you can see that it's a type noteport that's the service which is being
10:16 installed default what we are going to do is we are changing that type to load balancer and
10:23 usually when you change something to type load balancer there is an expectation that you are getting appear
10:28 trusses from external load balancer which could be your cloud load balancer in gcp or
10:35 aws or azure in our case contrail is going to provide that
10:40 appeatre so we do not need an external load balancer to do that so we are just going to patch the
10:47 service with that four lines of configuration
10:52 on the first one and now you can see right away the type changed from node port to load
11:00 balancer and we do have an external ip address and doing the same thing on the
11:06 second cluster now if we check
11:12 the services here what you will see is we have the same ip address on both clusters which is dot 2.
11:20 and this is a technique called anycast ip so we are going to advertise the same
11:26 ip address to all the clients which means the client in our case it's a
11:32 contract cluster which has pgp running is going to equally distribute or almost
11:38 equally distribute the traffic across both clusters holding that application
11:43 and that's because we are advertising the same ip address we also could advertise different ip addresses but i
11:50 just want to demonstrate that through bgp we support the anycast where
11:56 bgp is smart enough to detect hey behind that single ip address i do have
12:01 different destinations now what we have not done yet is to create the control plane federation
12:08 what we have in place right now is we have three clusters and all three clusters have a local bgp router
12:15 configured and we can see that if we go into the bgp routers over here
12:21 oh sorry that one already has it configured let's go to this one
12:27 so the cluster 3 has now bgp has only oh i pre-configured them already okay so
12:34 we can basically skip that step that's okay saves us some time so what you can see here on our first
12:42 cluster we do have uh our local cluster so that's the representation of our local bgp
12:48 node and we do have a representation of the third cluster as a bgp neighbor and
12:53 we do have a representation of the second cluster as a php controller
12:59 basically all we need to tell is the ip addresses and that's going to establish a
13:04 b2p connection between all three clusters so basically what we have in place is a fully federated control plane using
13:11 php where each cluster has the other cluster configured as a bgp
13:18 pier important to mention here those pgp routers you can see they are
13:23 config entries we are not running multiple bgp processors there is a single bgp process
13:30 per cluster and those guys here are just a representation of the php peers
13:38 likewise you cannot only add contrail clusters spgps you could add any pgp
13:45 device sap here so you can use a router francisco routers from jupiter
13:51 or bird or fr or whatever kind of php software you want to use
13:56 it's a fully compliant pgp implementation itself so because i have all the bgp so um
14:03 https already set up you can basically skip that step i'm just going to give you some introduction on how the
14:09 manifest look looks like um with all kubernetes resource it has a name and a
14:15 namespace and the important pieces here are the ip addresses which are used to establish
14:21 the peering and also the autonomous system number which is again going back to how pgp works you
14:28 can assign different autonomous system numbers in our case we are using the same as number for all
14:35 b2p routers and that basically means we are
14:41 running internal bgp versus external bgp if you would use different autonomous
14:46 system numbers again that's very heavy on the networking side it's not really important for that um
14:53 demonstration over here you you mentioned that you're you're only running one bgp process i assume you
14:58 mean that there's some sort of fail over there right like that there's oh yes absolutely so
15:05 there's just not one process per bg uh bgp router entry in right
15:12 absolutely okay we can run any number of bgp controllers in the cluster and they
15:17 are always fully synced um so they are not running in any kind of active passive mode
15:24 in fact all p2p instances are always active active but
15:30 as you said they are not on a peer basis all pgp
15:35 instances connect to all bgp peers as configured over here
15:42 and also each compute node would connect to multiple control nodes and the control nodes are active active
15:51 and they are paired by a pgp even if one control node goes down the other control node picks it up
15:58 hey michael not to go back too far but i keep getting caught up on this so the can you just explain again real quick in
16:04 the manifesto the route target list is that like a bgp prefix or like an acl or is that actually establishing neighbors
16:11 or what it what is that actually doing there so the the road target itself tells p2p
16:17 that virtual networks belong together in bgp so it makes bgp to exchange routes
16:25 between so like an asmr works like an asn or something like that kubernetes has the best analogy here a route
16:31 target's like a label that we applied to a prefix and then the the routing instances themselves
16:37 like the virtual networks have a will match on a set of labels a set of route targets in this case to decide which
16:44 routes to pull in from all of the routes that it's been advertised so we attach this route target label to this the same
16:50 route target label to two virtual networks and then bgp knows to blend them together into one virtual network
16:56 that helps a lot because i i don't know why i was so caught up on that it was just so thank you that yeah that actually
17:02 worked really well just using labels like application labels and things like that i can map everything together and
17:07 it knows to exchange realms and then there are some very interesting quirks on on road targets because
17:14 you cannot simply define a route target you can also define the direction so you can basically say
17:21 you can differentiate between import and export so you can say one virtual network is only importing a certain
17:27 route target and is exporting a different route tag and we will see that later on in prasad's
17:33 demonstration you can create interesting concepts with hubba and spoke where you basically can say you have one hub
17:39 virtual network which is allowed to talk with all the spokes but the spokes cannot talk to each other by using
17:45 asymmetric raw target export so it's a little bit more powerful than just a label itself
17:52 yep no the good stuff thank you okay so we have the bgp peering up and
17:57 running so rods can be exchanged but as we just have been on the topic of broad
18:03 targets just um to remind everybody what we wanted to do is to
18:08 allow communication from the pod network in cluster 3 to the service network in
18:14 cluster one and two now in order to do that we need to
18:19 set up the road targets because right now the pod network in cluster three hopefully does not have the road target
18:26 configured so let me quickly check that so we go to the default port network and
18:33 we can see here it's a little bit overload with information but there's no route target
18:39 on that default port network in cluster 3 that means right now bgp
18:45 is not establishing a communication path between the spot network and those two
18:51 service networks in order to exchange routing information what we can do is we are simply adding
18:58 the same route target to this port network over here and that again is very simple
19:04 we can just patch the existing default port network
19:11 and if we go back here and we check it again you will see now
19:18 we added the same route target to the pod network
19:23 and now bgp understands that there is a relationship between those three networks and pgp is
19:31 allowing to exchange routing information which means we do have a path from this spot network to the service
19:38 network in the first cluster and to the service network in the second cluster now because we're using an increase on
19:44 cluster one and cluster two it's not enough to work with ipa trusts because the increase is basically checking for the
19:51 fqdn you are using when you are doing the http request so what we need to do next in
19:58 the third cluster is to inject some dns resolution for this ip address
20:04 and remember that's the ip address we are advertising from cluster one and cluster two the same ip address being
20:10 advertised through bgp so by creating a separate namespace and creating a service in cluster tree
20:18 we are simply generating a synthetic dns entry which basically
20:24 resolves a certain url or a certain fqdn to this ip address we
20:31 are exporting in the two clusters so let's check that service here
20:38 and we have the service and that service is basically saying that myapp.apps
20:44 is resolving to 192.168.
20:50 and the last step of the demonstration is basically to create a pot on the third cluster which is going to send
20:57 some http requests to cluster one and cluster two and what we expect is that we see
21:05 responses coming back from the two parts on the two clusters by
21:11 accessing this url over here and this url again is front-ended by the
21:18 increase on both clusters so let's try that
21:26 and photos
21:32 and just a few words on um the url we are using here
21:38 so that one is defined in the increase if you remember or can quickly go back to the increase we
21:43 created so basically we are using a wildcard and say everything which goes to appsdemo.com forwarded to my service
21:51 and that's what we have on both clusters so the url we are accessing is exactly
21:57 that it's myapp.appstoredemo.com and
22:03 now let's try it out okay so you can see that and i'm going to
22:09 stop it here so we can take a little bit more detailed look into it the
22:14 pot hello world one one cluster two is replying on the first request the pot hello world
22:21 one on the first cluster is replying to the second request
22:26 zero on first cluster on the third request and then zero on first cluster to the fourth request that's why i said
22:33 it's almost equal distribution um you will see and that's based on multiple factors um on
22:40 on the entropy um how much different your source type p addresses are and we can
22:45 influence that kind of load balancing based on the tuple we see um consisting
22:51 of social peer trust destination ip address ports protocols we can
22:57 more equally distributed or less equally distributed based on certain requirements
23:03 but in general what you can see is that the requests are being served by all
23:09 four parts two parts on the first cluster and just to show that back here
23:16 hey michael so you can see yes i know i totally cut you off there apologies but but what we're looking at
23:22 here we are we're using any cast this looks like dns round robin so are we doing like dns ron robin here where
23:29 we're sending between clusters or are we leveraging any cast across the clusters to also distribute this
23:35 and then you also touched on like ecmp and things like that potentially so we are just using anycast um
23:43 what we do on the third cluster is we are resolving apps sorry myapp.apps
23:49 to a single ip address so the dns entry for this url does not
23:55 have multiple iphones so there is no dns round robin at all okay okay that is pure
24:02 anycast because the traffic goes out to this thing like address and bgp internally
24:08 is distributing this traffic across the two clusters i have a follow-up question
24:14 to that michael um for that particular use case this seems like overkill if i just wanted to load balance between two
24:21 different applications running two different clusters i could use dns round robin that would be real easy so what
24:26 would be a more i guess real world application of what you're showing where you want this sort
24:32 of virtual networks and subnets that are spanning multiple clusters
24:38 one use case is if you don't have a dns federation between the clusters usually your core dns only takes care
24:46 for the internal dns resolution if you want to have dns federated across different
24:52 clusters you need to install additional software you need external
24:57 dns for example which is just coming to to live
25:02 or you would have to coordinate with an external dns system
25:08 but this is not limited to just dns based communications so you can use that to
25:15 exchange routing information between just the plain service so what we have done and again you're
25:22 absolutely right um for for that kind of setup it would be a little bit overkill i just want to use this to demonstrate
25:28 some of the capabilities what you also can do at the same time is you can
25:34 just natively export the pod network from one cluster to the
25:39 next cluster so you one pot in cluster three can natively talk to another part
25:45 in cluster one or you can just export the default
25:51 service network and if you don't have dns resolution then you don't go usually through a dns
25:58 front robin but you can directly rely on ip reachability so it basically saves you the pain of federating your dns
26:05 which there is no really good automated solution in place today yeah and if i can just add to that another benefit
26:12 that we get with anycast is um any cast will like the the clusters are all
26:17 basically directed uh directly connected in this scenario but with anycast if there was some distance between the
26:23 clusters anycast will pick the closest cluster based on vgp
26:28 but an even cooler benefit is the advertisements of the external ips are
26:35 tied to service availability so as the service comes up if it's healthy if it has enough back ends contrail will
26:41 originate that external ip using vgp if the cluster fails if the app fails the route gets withdrawn so you get failover
26:47 between all of the members of the anycast group and that's like you can do you can do
26:53 all of this with dns but with dns you would need to monitor the endpoints pull out records as service went down like
26:59 you you basically need to wrap an anycast load balancing mechanism in additional resiliency to deal with
27:05 failure detection whereas with any cast you don't so you would actually use the two concepts together i would probably front end this
27:12 type of setup with round robin dns and use any cast to pick the right set of clusters for each of the
27:20 available back ends yeah because and to add to that because you're advertising from a dns
27:26 perspective and again i'm going to pau stop after this but to your point if i configure my dns to
27:33 point to one specific ip that is in anycast configuration across
27:39 my clusters problem solved at that point right because bgp will pull a bad peer out of
27:45 out of the routing and be able to distribute appropriately this is actually pretty cool this is
27:51 actually pretty cool so thank you well thank you both for the great question it is definitely overkill in
27:56 this case but it's uh it demonstrates the concept if you go through the kubernetes
28:02 documentation around service network around services they do have one paragraph on why they don't rely on dns
28:10 for various reasons and that's mainly around tpl you you don't know how the dns clients
28:16 are being configured you could get stuck with old dns records and there are a lot of problems around just relying on dns
28:24 but combining the two having dns to provide the name resolution to an anycast ip address
28:29 gives you basically the best of both worlds because on bgp we know the availability of a certain path and if
28:36 that path is for whatever reason not available then we withdraw that path from the routing and the cool thing here
28:43 is that our bgp availability for the path is influenced by the availability of end
28:51 points so if one pot goes down in a service we are withdrawing that route to that
28:56 pot from the bgp process itself so that's the level of interaction we have between
29:02 kubernetes itself and um networking concepts like pgp
29:08 so if i put this instance say i put something in aws azure gcp
29:14 and advertise can you do it can you do an anycast advertisement across those
29:20 clouds and use something like cloudflare to front end my dns and distribute across those different cloud providers
29:26 or even on-prem as well absolutely um the only requirement we have between the three clusters or any
29:33 clusters is ip reachability very right
29:38 yes exactly very random problem is if you can't have extra iphones if you have to network at rest translate you have a
29:45 problem because pgp pro nature does not support uh network and first translation okay cool thank you
29:51 and with that we are basically true just to show the expected output is more or less uh matching what we have seen here
29:59 and that more or less concludes my demonstration and again it's not necessarily the use case you would use
30:05 it for it's just here to show you how we interact with the resources
30:11 and some of the capabilities around multi-cluster and control plane federation
30:16 you can be really creative on what you are going to use that kind of technology for